





I. Introduction▲
Le test à données aléatoires (en anglais : fuzzing ou fuzz testing) est une technique de test consistant à injecter des données invalides, inattendues ou aléatoires en entrée d’un traitement informatisé. Si le logiciel testé échoue, par exemple en se terminant ou en affichant un message d’erreur, alors un défaut doit être corrigé.
Le test à données aléatoires est une technique à la fois simple et efficace pour mettre à jour les défauts d’un logiciel. Google a ainsi découvert plus de 20 000 défauts dans près de 300 projets source ouverte, grâce à son programme OSS Fuzz [1]Programme OSS Fuzz de Google, lancé en 2016. En 2014, la faille du shell Unix connue sous le nom de ShellShock a été découverte par un groupe de chercheurs appliquant le test à données aléatoires [2]La faille ShellShock a été découverte grâce au fuzzing. Plus récemment, la faille Heartbleed, touchant la bibliothèque OpenSSL, aurait pu être évitée si un test à données aléatoires avait été mis en place [3]HeartBleed aurait pu être évitée avec du fuzzing.
On le constate par ces exemples, le test à données aléatoires permet réellement de détecter des erreurs logicielles, dont certaines constituent également des failles de sécurité. Ainsi, de nombreux chercheurs en sécurité, mais également des pirates, utilisent cette technique pour trouver des défauts logiciels, qui dans certains cas peuvent être utilisés contre le programme comportant ces failles.
II. Difficultés liées aux tests à données aléatoires▲
D’ordinaire, les tests à données aléatoires sont exécutés par l’équipe de sécurité, le plus souvent en fin de projet, peu avant la mise en service de l’application. Cette manière de procéder n’est pas sans poser quelques problèmes, que nous passons en revue dans les paragraphes suivants.
II-A. Exécution dans les dernières phases du développement▲
Quand les tests à données aléatoires sont exécutés en fin de projet, la découverte de failles de sécurité peut conduire, soit au report du lancement de l’application, soit plus probablement à la mise en service d’une application présentant des failles de sécurité.
Par ailleurs, l’exécution de tests de sécurité avant la mise en service d’un logiciel est totalement inadaptée au développement informatique par les méthodes agiles actuelles. Il devient ainsi indispensable de repenser complètement la place occupée par les tests de sécurité. Ceux-ci doivent désormais s’intégrer dans un cycle de développement continu.
Dans le contexte agile, les tests à données aléatoires devraient être exécutés en continu, durant les tests d’intégration par exemple ou encore mieux durant les tests unitaires. Ceci permettrait aux équipes de programmeurs de corriger très tôt les erreurs dont souffrent leurs applications.
II-B. Difficulté à intégrer à la chaîne d’intégration continue▲
Il existe plusieurs outils de test de sécurité des applications (dynamic security application testing – DAST), dont certains comportent un module exécutant des tests à données aléatoires. Il est possible d’intégrer ces outils dans la chaîne d’intégration continue, mais la tâche n’est pas si facile, je parle d’expérience.
Il serait souhaitable que les tests à données aléatoires soient aussi faciles à intégrer que les tests unitaires par exemple. Ainsi, les tests à données aléatoires feraient partie de la panoplie des outils permettant d’atteindre le déploiement en continu préconisé par les méthodes agiles.
II-C. Faible performance des tests▲
Les outils de test de sécurité des applications (DAST) fonctionnent souvent dans un environnement de test distribué, autrement dit, les requêtes de l’outil transitent par un réseau. De plus en plus, les containers docker sont utilisés pour ces tests, de sorte que l’application sous test, ainsi que l’outil de test de sécurité, s’exécutent alors sur la même machine. Ceci minimise l’effet du réseau, sans pour autant éviter la sérialisation et la désérialisation des données.
Les tests à données aléatoires devraient dans la mesure du possible s’affranchir des réseaux ainsi que de la sérialisation et désérialisation des objets pour leur transport, ceci afin de minimiser leur temps d’exécution.
II-D. Grande quantité de données de test▲
Un test à données aléatoires, selon sa définition, est sensé tester des cas de données partiellement ou totalement mal formées, ce qui sous-entend un nombre énorme de cas de test. Imaginez le test d’un simple champ d’entrée d’un patronyme. Un test à données aléatoires devrait tester des chaînes de caractères comportant des combinaisons de caractères de tous les alphabets, les caractères spéciaux, ainsi que des chaînes très longues.
Il serait souhaitable de pouvoir limiter les cas de test à ceux connus pour être fréquemment à la source de failles de sécurité, notamment en fonction des technologies utilisées dans le projet sous test.
II-E. Les développeurs ne sont pas experts en sécurité▲
Pensez au nombre de compétences que doivent posséder les développeurs. Ils doivent maîtriser plusieurs langages de programmation des outils (éditeurs, outils de build, de test…), des frameworks (applications web, services, accès aux bases de données…), des technologies (cloud, serveurs…). Et en plus, ils doivent avoir des connaissances approfondies du métier pour lequel il développent des applications. Peut-on en plus leur demander d’être experts en sécurité, capables de développer des cas de test réalistes et efficaces ?
Un test à données aléatoires devrait pouvoir être exécuté par les développeurs, en requérant de leur part un minimum de connaissances en sécurité.
III. FuzzDbUnit apporte une solution▲
FuzzDbUnit espère apporter une solution aux problèmes signalés dans les paragraphes précédents. FuzzDbUnit est une extension à JUnit 5, permettant d’injecter des cas de test provenant de FuzzDb, une base de cas de test centrés sur la sécurité. Mais voyons plus en détail chacun de ces deux éléments.
III-A. Qu’est-ce que JUnit ?▲
Il est probablement inutile de présenter JUnit [4], un outil de tests unitaires pour le langage java. Dans sa version JUnit 5, cet outil offre la possibilité de créer très facilement des tests paramétrés. La source des paramètres peut être de plusieurs formes, par exemple d’un vecteur, d’un fichier ou d’une fonction générant les paramètres à la volée.
Malgré son nom, JUnit, son utilisation ne se limite pas aux tests unitaires. En effet, JUnit peut très bien servir dans des tests d’intégration, où sont testées par exemple des classes de service. En combinant JUnit avec un client HTTP, il est également possible de réaliser des tests d’interface qui enverront des requêtes à une application web ou à un service web en passant par un réseau.
III-B. Qu’est-ce que FuzzDb ?▲
FuzzDB [5]FuzzDB est une base de données rassemblant des cas de tests connus pour constituer des vecteurs d’attaque. Cette base de données a été compilée au cours des années par un chercheur en sécurité, Adam Muntner, qui la propose en source ouverte. Cette base de données est utilisée dans plusieurs outils bien connus, notamment OWASP Zaproxy, BurpSuite ou encore Metasploit.
FuzzDb classe les cas de test en plusieurs types de figures, allant des classiques injections SQL, les Cross Site Scripting (XSS), les chemins d’accès, etc.
III-C. Pourquoi utiliser FuzzDbUnit ?▲
FuzzDbUnit, en s’intégrant avec JUnit, offre de nombreux avantages. Il permet d’effectuer des tests à données aléatoires au stade du développement déjà et donc de mettre en évidence des erreurs à un moment où il est encore peu coûteux de les corriger. En effet, des classes de validation, par exemple, pourront être testées dès la phase de tests unitaires. Pour des classes de service, les tests d’intégration seront visés. Les interfaces graphiques ou les services web quant à eux seront testés dans la phase de test fonctionnel.
FuzzDbUnit, avec la base de cas de tests de FuzzDB, concentre les tests sur les cas connus pour être problématiques : en réduisant le nombre de cas de test, on réduit d’autant la durée des tests. Si l’on ajoute à cela que les tests peuvent être exécutés sans appel au travers d’un réseau, leur durée en est ainsi réduite.
Finalement, en s’intégrant à JUnit, FuzzDbUnit est facile à intégrer au pipeline, il est donc à la portée de tous les développeurs. Ceux-ci bénéficient en outre de l’expertise en sécurité de Adam Muntner, au travers des données de FuzzDB.
IV. Comment utiliser FuzzDbUnit ?▲
FuzzDbUnit se base sur les notions de test paramétré et de source d’arguments définies dans Junit 5. Un test paramétré selon JUnit 5 consiste en une méthode de test, annotée avec @ParameterizedTest, et prenant un ou plusieurs arguments. Les valeurs assignées à ces arguments sont alors définies par une ou plusieurs sources d’arguments (@ArgumentsSource). Ces sources d’arguments peuvent être de différentes natures, comme une liste de valeurs (@ValueSource), un fichier CSV (@CsvFileSource) ou une énumération (@EnumSource). FuzzDbUnit se présente ainsi sous la forme d’une source d’arguments, appelée @FuzzSource. Cette annotation prend en paramètre le type de figures d’attaque qui seront passées à la méthode de test. Ces figures d’attaque sont elles-mêmes rassemblées dans une énumération, ce qui en facilite le choix, dès lors que votre IDE favori vous les propose avec sa fonction de complétion.
Quelques exemples mettront mieux en lumière la manière de tester avec FuzzDbUnit.
FuzzDbUnit étant disponible dans le dépôt Maven Central, on l’intégrera donc à son projet en le déclarant en dépendance, en prenant soin de le limiter au périmètre du test. Comme FuzzDbUnit se base sur JUnit 5, il est également nécessaire de déclarer cette bibliothèque dans les dépendances. Ceci donne les déclarations suivantes, pour Maven et Gradle :
Maven
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
<dependency>
<groupId>com.github.fuzzdbunit<groupId>
<artifactId>fuzzdbunit</artifactId>
<version>0.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.1.0</version>
<scope>test</scope>
</dependency>
Gradle
2.
3.
4.
Dependencies {
testImplementation("org.junit.jupiter:junit-jupiter-engine:5.1.0")
testImplementation("com.github.fuzzdbunit:fuzzdbunit:0.3")
}
FuzzDbUnit étant maintenant déclaré dans le projet, voyons comment coder les tests.
IV-A. Utilisation en test unitaire▲
Dans l’exemple suivant, on veut tester une classe validant des données en entrée.
2.
3.
4.
5.
6.
7.
@ParameterizedTest(name = "Fuzz testing validator")
@FuzzSource(file = FuzzFile.ATTACK_XSS_XSS_URI)
void testValidationWithFuzzUnit(String content) {
Assertions.assertThrows(ValidationException.class, () -> {
Greeting g = Greeting.build(10, content);
}, "Failed with ["+content+"]");
}
Dans JUnit 5, un test paramétré est tout d’abord défini par une l’annotation @ParameterizedTest de JUnit (ligne 1). Il est représenté par une méthode prenant un paramètre, comme dans le cas ci-dessus (ligne 3). Cette méthode sera appelée pour chacune des valeurs figurant dans la source de données associée (ligne 2). JUnit propose plusieurs types de sources de valeurs, comme @ValueSource qui utilise un vecteur de valeurs, @EnumSource qui itère sur les éléments d’une Enumeration, ou @CsvSource qui lit les données d’un fichier CSV.
Pour réaliser un test à données aléatoires, on déclare l’annotation @FuzzSource offerte par FuzzDbUnit (ligne 2), en précisant le fichier de données aléatoires à lire. Dans le test présenté ici, on a choisi : FuzzFile.ATTACK_XSS_XSS_URI. Afin de faciliter la sélection de ce fichier, une énumération est proposée : FuzzFile. Votre éditeur de code affichera la liste complète des fichiers disponibles dans FuzzDb.
L’implémentation de la méthode de test peut surprendre au premier abord : nous sommes en effet habitués à des tests positifs, alors que les tests à données aléatoires sont des tests destructifs, lors desquels nous cherchons à produire des erreurs. Dans l’exemple ci-dessus, nous attendons donc que la classe de validation produise des exceptions, ici du type ValidationException. Les tests à données aléatoires permettent souvent de mettre en évidence un autre type d’exceptions : des NullPointerException. Ils contribuent ainsi, non seulement à la sécurité d’une application, mais aussi à sa qualité générale.
IV-B. Utilisation en test d’intégration▲
Cet autre exemple montre l’utilisation de FuzzDbUnit lors du test d’intégration d’un service web. Ce service et les tests correspondants sont réalisés au moyen du framework quarkus.
2.
3.
4.
5.
6.
7.
8.
@ParameterizedTest
@FuzzSource(file = FuzzFile.ATTACK_SQL_INJECTION_DETECT_GENERICBLIND)
void whenGetBooksByTitle_thenBookShouldNotBeFound(String name) {
given().contentType(ContentType.JSON).param("query", name)
.when().get(libraryEndpoint)
.then().statusCode(200)
.body("size()", is(0));
}
Détaillons tout d’abord les différentes parties du test lui-même. En ligne 4, une requête pour un élément de type JSON est préparée, incorporant un paramètre nommé « query » (ligne 4). La requête de type GET est envoyée à un endpoint (ligne 5), dont on attend une réponse de succès (code 200 en ligne 6). Enfin, le corps de la réponse est vide, car le service n’est pas censé trouver l’objet demandé.
Comme dans l’exemple précédent, le test est paramétré (ligne 1). La source de données aléatoires est également signalée par l’annotation @FuzzSource (ligne 2). Dans ce deuxième cas, on veut vérifier le comportement du service lors d’attaques de type injection SQL. Si le service est insensible à ce type d’injections, alors il répondra par un code 200, sans retourner de données, d’où la taille de la réponse : zéro. Le test sera alors passé avec succès. Si au contraire le service est sujet aux attaques par injection SQL, alors il répondra, soit par une erreur (p.ex. un code 500, erreur de serveur), soit pire, en retournant des données qui n’étaient probablement pas prévues par les développeurs. Dans ce cas, la taille de la réponse sera plus grande que zéro et le test échouera (ligne 7). Ainsi conçu, ce test devrait détecter un défaut dû à une injection SQL, tout en évitant les faux positifs.
IV-C. Utilisation en test fonctionnel▲
Il est également possible de réaliser des tests à données aléatoires lors de tests fonctionnels, en utilisant le framework Selenium par exemple. Selenium permet notamment de piloter un navigateur à partir de code, java par exemple. Il est ainsi possible d’automatiser les tests fonctionnels, en exécutant des opérations sur les éléments de la page HTML.
Voici l’exemple du test fonctionnel d’une page de l’application WebGoat, une application développée comme exemple pour de nombreuses failles informatiques. La page testée présente un champ pour l’entrée d’un code de commande à trois chiffres :
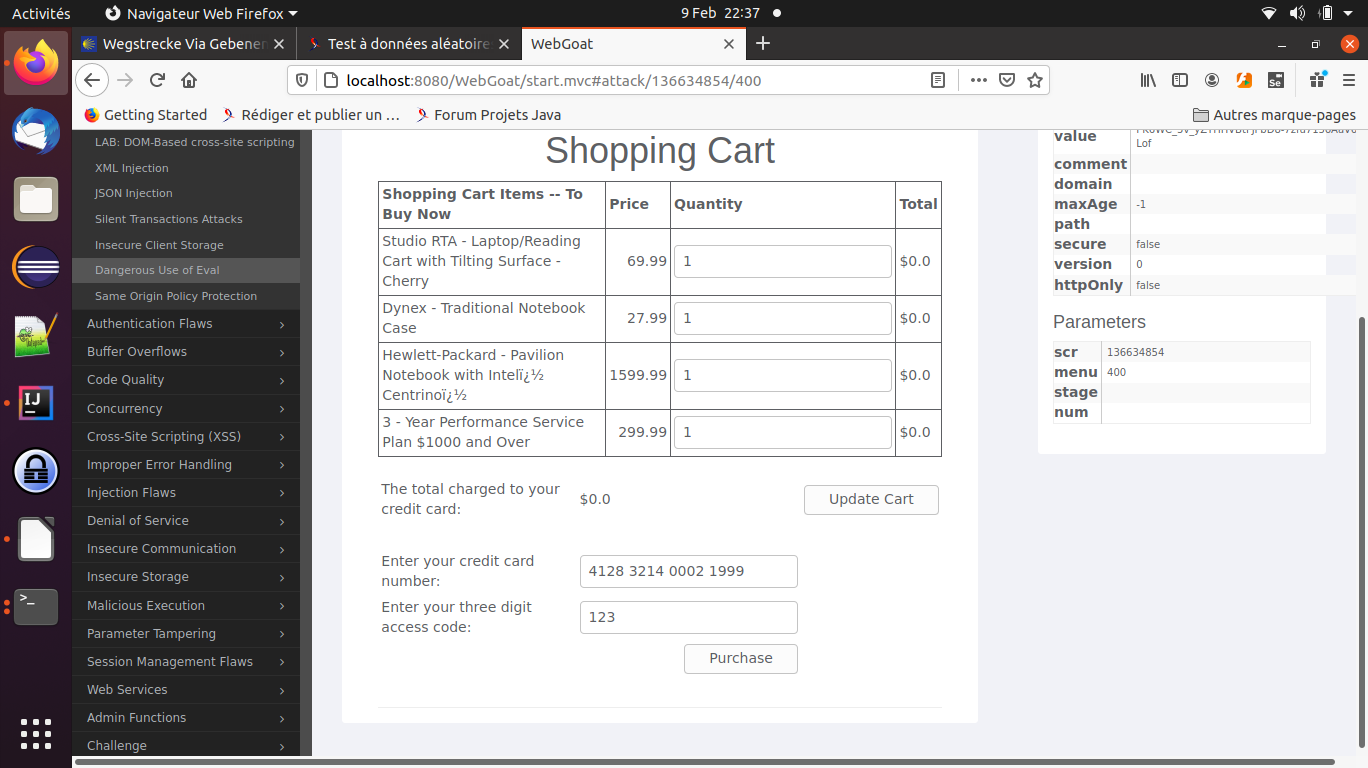
Selenium permet au code de piloter le navigateur comme le ferait un utilisateur réel. Dans le cas de la page que nous voulons tester, le code sélectionne le champ d’entrée, y introduit un texte, puis clique sur le bouton de commande (« Purchase »).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
@ParameterizedTest
@FuzzSource(file = FuzzFile.ATTACK_XSS_XSS_OTHER)
public void testWebgoatWithSeleniumFuzzingOptimized(String field) {
// chercher le champ d’entrée à tester
WebElement fieldElement = driver.findElement(By.id("field1"));
// renseigner le champ avec la valeur de test
fieldElement.clear();
fieldElement.sendKeys(field) ;
// chercher le bouton de confirmation et cliquer dessus
driver.findElement(By.cssSelector("td:nth-child(1) > input")).click();
// Vérification de la réponse du site. Quatre cas peuvent se présenter:
// 1) un popup signale une erreur de la valeur d’entrée; ceci est la réponse espérée
// 2) un popup confirme la commande
// 3) pas de popup du tout
// 4) un second popup s’ouvre à cause de l’injection XSS
Alert alertPopup = null;
try {
// cas 1 et 2
alertPopup = driver.switchTo().alert();
assertThat(alertPopup.getText(), containsString("Whoops: You entered an incorrect access code of"));
} catch (NoAlertPresentException nape) {
// cas 3
fail("Popup has not been opened: " + nape.getClass());
} finally {
// retourner à la page initiale pour la prochaine valeur de test
if (alertPopup != null) {
alertPopup.accept();
}
// cas 4 soulève une exception à l’appel ci-dessous
navigateToTestedPage();
}
}
Quand les opérations de sélection, de frappe de texte et de clique de bouton sont terminées (lignes 1 à 10), le site est appelé par le navigateur et la page est rafraîchie. On passe alors à l’évaluation de la réponse du site sous test (ligne 20 et suivantes). Quatre réactions différentes peuvent être observées, en fonction de la valeur de l’argument :
- un popup s’ouvre et signale que la valeur fournie n’est pas valable ; c’est la réponse souhaitée de la part du site. L’appel à assertThat (ligne 21) détecte la présence du message d’erreur attendu. Le test est réussi ;
- un popup s’ouvre pour indiquer que la commande a été acceptée ; comme les valeurs de test représentent une attaque de type XSS, ce cas signale que le site n’a pas réussi à détecter l’attaque. L’appel à assertThat (ligne 21) ne trouve pas le message d’erreur espéré et lève une exception. Le test échoue ;
- dans certains cas de test, le site ne répond pas du tout, aucun popup n’apparaît, d’où la présence de l’exception NoAlertPresentException (ligne 24) lancée par Selenium ;
- dans ce dernier cas, le site se fait prendre par l’injection XSS et ouvre un popup lors du chargement de la page suivant la confirmation. Le « focus » passe alors sur ce popup, de sorte que Selenium ne parvient pas à naviguer en retour vers la page initiale et il émet une exception pour le signaler. Ceci se produit à l’intérieur de la méthode navigateToTestedPage() (ligne 31).
Cet exemple montre que FuzzDbUnit peut être aussi utilisé lors de tests fonctionnels, par exemple avec Selenium. On remarque également que les réactions d’un site soumis à l’entrée de valeurs aléatoires peuvent être multiples, ce qui complique un peu l’évaluation des résultats. Mais de tels tests permettent vraiment de révéler de nombreuses erreurs de programmation, qui sans cela passeraient inaperçues.
IV-D. Test à paramètres multiples▲
Dans certains cas, vous serez appelés à tester une méthode prenant plusieurs paramètres. En conséquence, la méthode de test proprement dite aura plusieurs paramètres également. Pour illustrer ce cas, reprenons notre deuxième exemple et complétons-le avec un paramètre supplémentaire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
@ParameterizedTest
@FuzzSources( {
@FuzzSource(file = FuzzFile.ATTACK_SQL_INJECTION_DETECT_GENERICBLIND,
paddingValue=""),
@FuzzSource(file = FuzzFile.ATTACK_SQL_INJECTION_DETECT_GENERIC_SQLI,
paddingValue=null)
})
void whenGetBooksByNameAndTitle_thenBookShouldNotBeFound(String name, String title) {
given().contentType(ContentType.JSON)
.param("query", name)
.param("title", title)
.when().get(libraryEndpoint)
.then().statusCode(200)
.body("size()", is(0));
}
Deux particularités sont à signaler. Tout d’abord, il faut fournir maintenant deux sources de valeurs, l’une pour renseigner le premier paramètre (ligne 3), l’autre pour le second paramètre de la méthode de test (ligne 5). Ces deux @FuzzSource sont encadrées par une annotation @FuzzSources (ligne 2). Nous choisissons pour ce test deux fichiers de données aléatoires différents. Ce qui nous amène à la seconde particularité, les paddingValues (ligne 4 et 6).
Selon toute probabilité, les deux fichiers choisis ne contiendront pas le même nombre de données de test. Lorsque toutes les valeurs du fichier le plus court seront épuisées, que va-t-il se passer pour les valeurs restantes du fichier le plus long ? C’est pour régler ce cas que sont utilisées les paddingValues. En effet, ces valeurs remplaceront en quelque sorte les valeurs manquantes du fichier le plus court, pendant que les valeurs du fichier le plus long continueront d’être envoyées en argument, jusqu’à leur épuisement. Ainsi, toutes les valeurs de test des deux sources sont utilisées.
V. Conclusion▲
Nous l’avons vu, les tests à données aléatoires sont un moyen efficace de mettre au jour des erreurs logicielles et devraient ainsi faire partie des pratiques habituelles des développeurs. Ce n’est toutefois pas le cas, ceci pour différentes raisons, notamment parce que les tests à données aléatoires sont actuellement typiquement une activité des testeurs en sécurité. FuzzDbUnit représente une tentative de mettre le test à données aléatoires à la portée des développeurs et ainsi de promouvoir cette pratique dans des phases avancées du développement.
FuzzDbUnit est une extension aux tests paramétrés de JUnit, combinée à des cas de test compilés par un expert en sécurité. Cette combinaison permet d’exécuter des tests à données aléatoires orientés sécurité durant les tests unitaires, les tests d’intégration et même les tests fonctionnels. Par ailleurs, l’utilisation de JUnit, bien connu des développeurs, permet une intégration facile des tests à données aléatoires dans le cycle de développement.
FuzzDbUnit fournit pour l’instant une fonctionnalité de base. Des améliorations sont possibles, et vos retours permettront de les orienter. Laissez-moi vos suggestions dans les commentaires de cet article, ou sur le dépôt de code de FuzzDbUnit [6]FuzzDbUnit.
VI. Références▲
[1] https://github.com/google/oss-fuzz
[2] https://en.wikipedia.org/wiki/Shellshock_(software_bug)
[3] https://blog.hboeck.de/archives/868-How-Heartbleed-couldve-been-found.html
VII. Remerciements▲
Merci à Mikael Baron de sa relecture technique et de sa patience pour guider mes premiers pas avec le Kit DVP. Mes remerciements vont également à escartefigue pour la correction orthographique.